어떤 시스템인가
- DB 접속하여 데이터를 실시간 주기로 데이터를 targetDB에 적재하는 스케줄러 배치 모듈
- 서버 중단 없이 스케줄 주기 동적 변경
- 서버 중단 없이 이관 DB 추가 하여 스케줄 배치 수행
- 이관해야 하는 DB 접속수가 늘어나도 각각 스케쥴 배치 수행
- 기본적 서버 이중화 이지만 서버가 늘어나도 서버별 스케줄 배치 수행 (서버 클러스터링)
- 한쪽 서버가 죽어도 나머지 서버가 죽은 서버의 스케줄 배치 까지 수행
왜 Quartz를 사용 하였는가

- 서버 클러스터링을 사용하기 위해
- 서버 클러스터링이 필요한 이유는 만들고자 하는 배치 스케줄 모듈이 시간이 지날수록 이관해야 하는 DB가 늘어나는 만큼 서버 부하를 분산시키기 위해
quartz clsutering 동작 과정
아래 표는 실제 서버를 각각 shutdown 시켜가면서 quartz clustering 동작을 눈으로 확인한 과정을 적은 것이다.
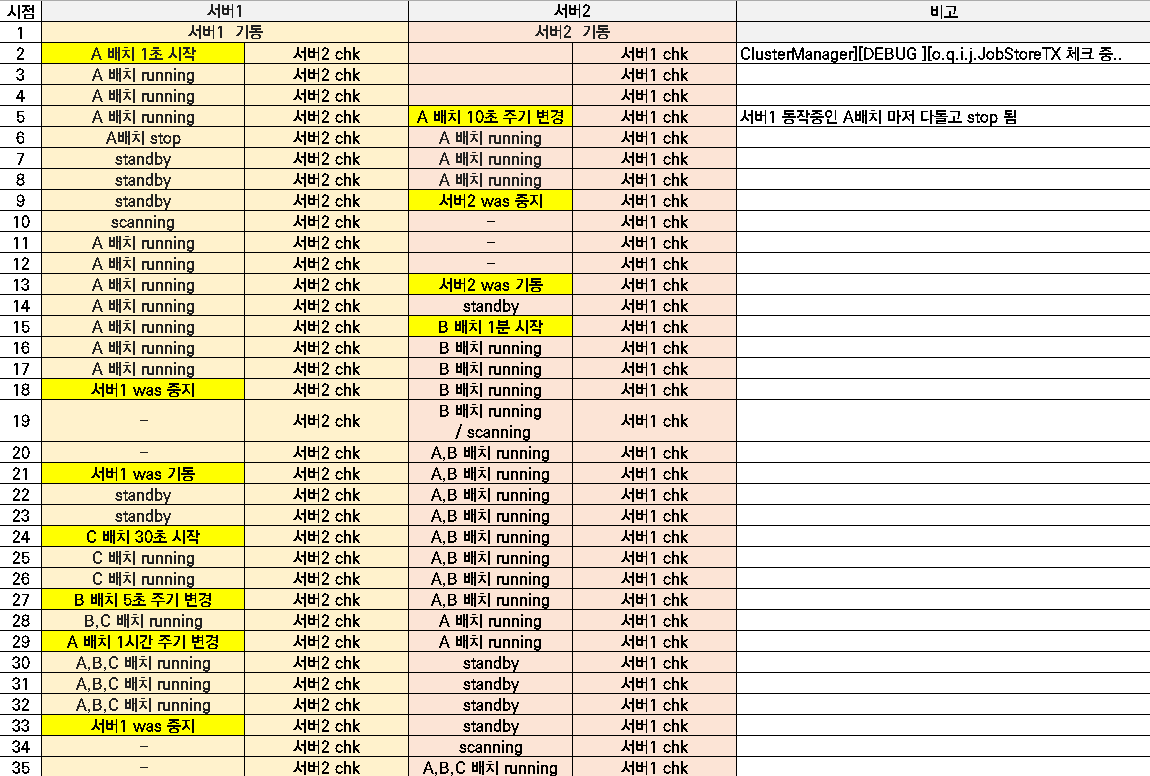
그럼 도대체 clustering 기능은 어떻게 사용한단 말인가
- quartz 테이블 생성 [생성 스크립트 이동]
- quartz instance property 설정
- quartz jobStore property 설정 (property 설정 방법은 아래 quartz 설정 방법 부분 참고)
Quartz instance property 에 대한 공식 설명을 먼저 보자
org.quartz.scheduler.instanceName
Can be any string, and the value has no meaning to the scheduler itself - but rather serves as a mechanism for client code to distinguish schedulers when multiple instances are used within the same program. If you are using the clustering features, you must use the same name for every instance in the cluster that is ‘logically’ the same Scheduler.
org.quartz.scheduler.instanceId
Can be any string, but must be unique for all schedulers working as if they are the same ‘logical’ Scheduler within a cluster. You may use the value “AUTO” as the instanceId if you wish the Id to be generated for you. Or the value “SYS_PROP” if you want the value to come from the system property “org.quartz.scheduler.instanceId”.
정리하면 cluster mode를 사용하려면 같은 instanceName을 가진 서버별 고유에 instanceId를 가져야 cluster mode를 이용 할 수 있다는 뜻이다.
1 | // scheduler identity |
그 밖의 quartz config 설정은 quartz 레퍼런스 문서를 보는게 제일 정확하므로 참고하여 설정하면 된다.
Quartz 셋팅
프로젝트 환경 및 버전
Java8 + Spring 3.1.1 + Quartz 2.2.1 + Maven
Spring 4 일 경우는 아래 추가로 dependency 해주어야 한다.
1 | <dependency> |
해주지 않으면 org.springframework.scheduling.quartz 패키지가 존재 하지 않는다. (Spring 3은 spring-context-support dependency 안해줘도 됨)
Quartz Spring Bean 등록
1 |
|
객체 설명
SchedulerFactoryBean 객체 (org.springframework.scheduling.quartz)
Spring Framework에서 Quartz를 bean으로 관리하기 위해 필요한 클래스로 Spring에서 Quartz를 사용하기 위해 필요함
AutowiringSpringBeanJobFactory 객체
org.quartz.Job 을 implements한 Job 클래스내에서 @Autowired 할 수 있도록 하기 위해서 사용함
왜 필요한가
구현한 Job 클래스에서 주입 받아야 하는 경우가 반드시 존재 하기 때문이다.
예를 들면 DAO 클래스 이다. 필자 같은 경우는 데이터를 DB INSERT 해야하는 경우로 Job 클래스에 DAO를 반드시 주입받아야 하기에 반드시 필요했다.
만약 객체를 생성하지 않으면 @Autowired 해도 객체가 null 이다.
그럼 왜 AutowiringSpringBeanJobFactory 객체 생성해야 @Autowired 할 수 있었을까??
해당 내용은 Spring Container 어떻게 Bean을 관리하는지에 대한 개념을 알아야 이해 할 수 있으며 해당 개념을 필자도 알고 싶어서 조사해 봤다.
그냥 추가해야 된다는 것만 알고 넘어 가고 싶다면 다음 주제로 넘어가면 되고 Spring이 bean 관리 메커니즘에 대해 궁금 하다면 아래를 보자
1 | import org.quartz.spi.TriggerFiredBundle; |
// TODO Posting spring은 어떻게 bean관리를 하는가
Quartz 실행 화면
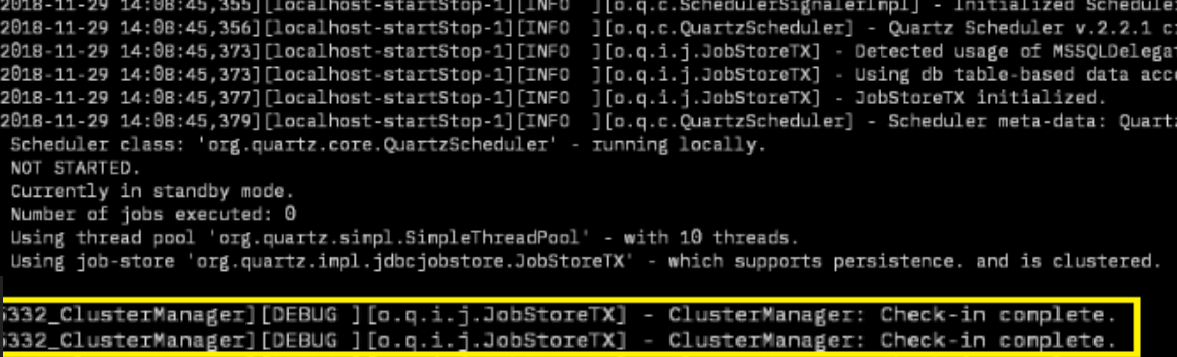
quartz 셋팅을 마치고 was를 기동하면 위 로그와 같이 quartz 버전, 클러스터 모드 on/off 여부, Thread pool 갯수 등 정보가 나온다.
cluster mode가 제대로 동작한다면 노란색 박스 로그와 같이 설정한 check interval time에 맞게 로그가 계속 찍힐 것이다.
다른 서버가 살아있는지 계속 체크하고 있는 것이다. (로그를 볼때는 debug 레벨로 해야 보임)
그 밖의
@DisallowConcurrentExecution
Thread Pool 기반으로 동작하는 Quatrz에서 Job에 대한 Thread 동시 접근으로 인해 데이터 중복을 방지하기 위한 어노테이션 인거 같다.
나는 동시접근 못하게 코드로 막았는데 이런게 있는줄 알았으면 쉽게 해결했을거 같다.